编译原理笔记 - Parser
Stone语言语法定义


- 规则中出现的 NUMBER 、IDENTIFIER 、STRING、OP与 EOL 都是终结符,分别表示整型字面量、标识符、字符串字面量、双目运算符与换行符类型。
- 非终结符 primary (基本构成元素)用于表示括号括起的表达式、整型字面量、标识符(即变量名)或字符串字面量。
- 非终结符 factor (因子)或表示一个 primary ,或表示 primary之前再添加一个 - 号的组合。
- expr (表达式)用于表示两个 factor 之间夹有一个双目运算符的组合。
- block (代码块)指的是由 {} 括起来的 statement(语句)序列statement 之间需要用分号或换行符(EOL)分隔。
- statement 可以是 if 语句、while 语句或仅仅是简单表达式语句(simple)。simple是仅由表达式(expr )构成的语句。
- 最后的 program 是一个非终结符,它可以包含分号或换行符,用于表示一句完整的语句。
设计Parser
作者提供了一个Parser库,它的功能仅是将 BNF 写成的语法规则改写为 Java 语言程序,这个库的实现将在第17章讲解,目前无需关注它的具体实现细节,先学习如何使用它构造出Parser。
BasicParser 类首先定义了大量 Parser 类型的字段,它们是将上一节中列出的 BNF 语法规则转换为 Java 语言后得到的结果。
据此定义的 Parser 对象能够根据各种类型的非终结符模式来执行语法分析。例如,将词法分析器作为参数,调用 program 字段的 parse 方法就能从词法分析器获取一行程序中包含的单词,并对其做语法分析,返回一棵抽象语法树。
1 | package stone; |
Parser类的使用
Parser类的方法: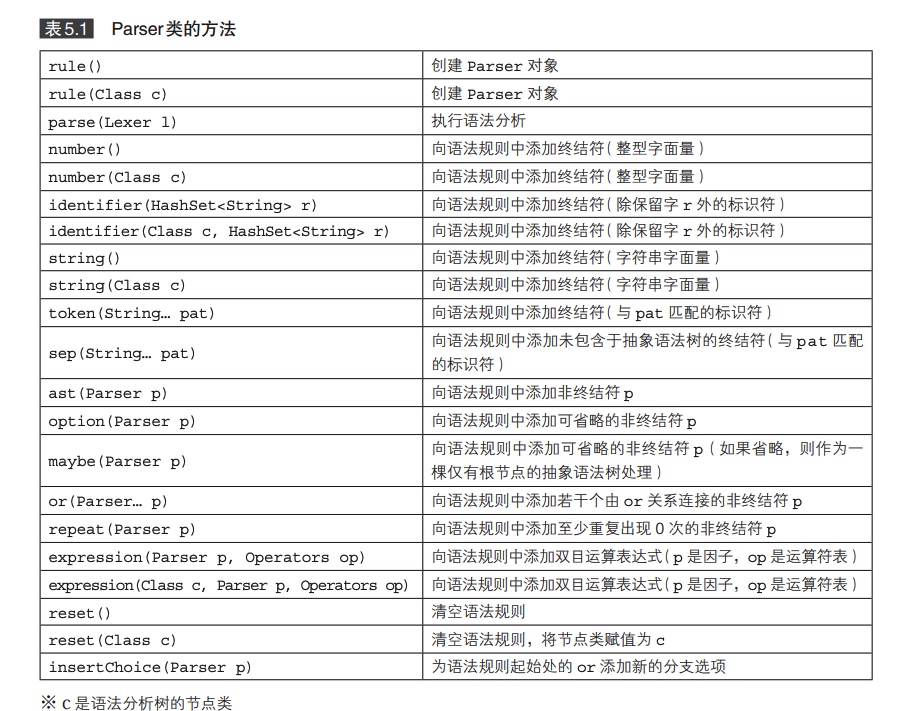
首先,假设我们要处理这样一条语法规则。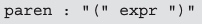
将它转换为 Java 语言后将得到下面的代码。
它先用rule创建了一个Parser对象,模式为空,然后需要按照出现顺序向模式添加终结符或者非终结符。
根据paren的模式,它包含左括号、非终结符expr、和右括号。这些模式需要依次添加进对应的Parser对象内。
这样一来,Parser 对象就能够表示某一特定的语法规则模式。该对象不仅能完整表示语法规则右半部的模式,也能表示模式的一部分。or 方法与repeat 方法能够表示 BNF 中由“| (或)”与“{}”构成的循环。
拿factor举例: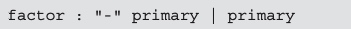
为方便阅读,此处省略了 rule 方法的参数。
factor 规则右侧的模式将匹配 primary 或是 - 号后接 primary 的组合。这里的代码调用了通过 rule 方法创建的 Parser 对象的 or 方法,并添加了两种分支模式。对该模式来说,factor 对应的 Parser 对象只要与两者中的一种匹配即可。
or 与 option 方法的参数对应的或是一个 Parser 对象,或是一个
由 rule() 开头的表达式。

BasicParser 类首先通过 rule 方法创建了一个 Parser 对象,且没
有调用其他任何方法,直接将该对象赋值给 expr0 字段。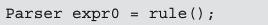
这里预先创建的 Parser 对象 expr0 之后将会被赋值给 expr 。语言处理器可以通过该对象依次创建与 primary 及 factor 对应的 Parser对象,最后再使用expression方法用 factor 将正确的模式添加至 expr0,完成一系列的处理。最终获得的对象(实际上即为 expr0)将被赋值给 expr。
非终结符 expr 的语法规则如下:
expression 方法:
Parser 类的 expression 方法能够简单地创建 expr 形式的双目运算表达式语法。可以匹配像 2 + 3 这种表达式。
运算符表以 Operators 对象的形式保存,它是 expression 方法的第 3 个参数。运算符能通过 add 方法逐一添加。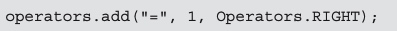
add 方法的参数分别是用于表示运算符的字符串、它的优先级以及左右结合顺序。用于表示优先级的数字是一个从 1 开始的 int 类型数值,该值越大,优先级越高。
add 方法的第 3 个参数如果是 Operators.LEFT ,则表示左结合。意思是两个运算符同时出现时,左边的优先级最高。
1 | 1 + 2 + 3 |
左侧优先的结果:
1 | ((1 + 2) + 3) |
如果是右侧优先:
1 | (1 + (2 + 3)) |
由语法分析器(Parser)生成的抽象语法树(AST)

其中,叶节点是用于表示与该模式匹配的单词(即终结符)的 ASTLeaf 象,它们的直接父节点是一个 ASTList 对象,构成了这棵子树的根节点。
如果 rule 方法的参数为 java.lang.Class 对象,抽象语法树的根节点就是一个该类的对象。
此外,number 与 identifier 等方法除了能够向模式添加终结符,还可以接收 java.lang.Class 对象作为参数,生成这种类型的叶节点对象。
例如:

以上方式改写代码, 叶节点将改为 NumberLiteral 对象,根节点则将是 一个 BinaryExpr 对象。
如果语法规则的模式中含有非终结符,与该非终结符匹配的单词序列将暂时原样保留在子树中。让我们来看一个例子,下面的模式使用了上面提到的 adder 。

红色的部分就是ast(adder)。ast 方法接收的 Parser 对象所表示的模式相匹配的部分都会首先作为一棵子树呈现,该子树能够表示 Parser 对象中的结构关系。这棵子树的根节点将成为某些由上一层模式生成的节点的直接子节点。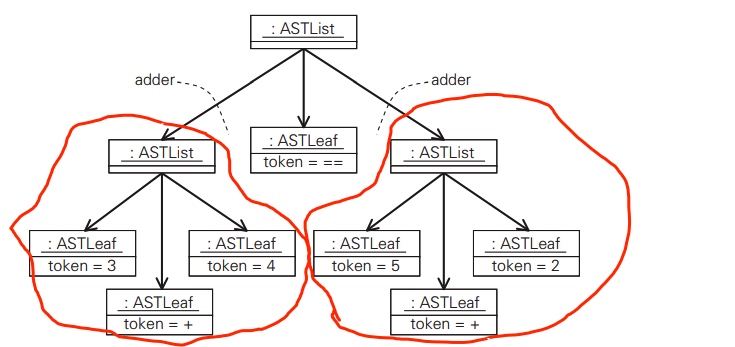
最后,我们来看一下如何将非终结符 program 的语法规则改写为 Java 语言。
表示匹配statement或者为空(Null)。
测试Parser
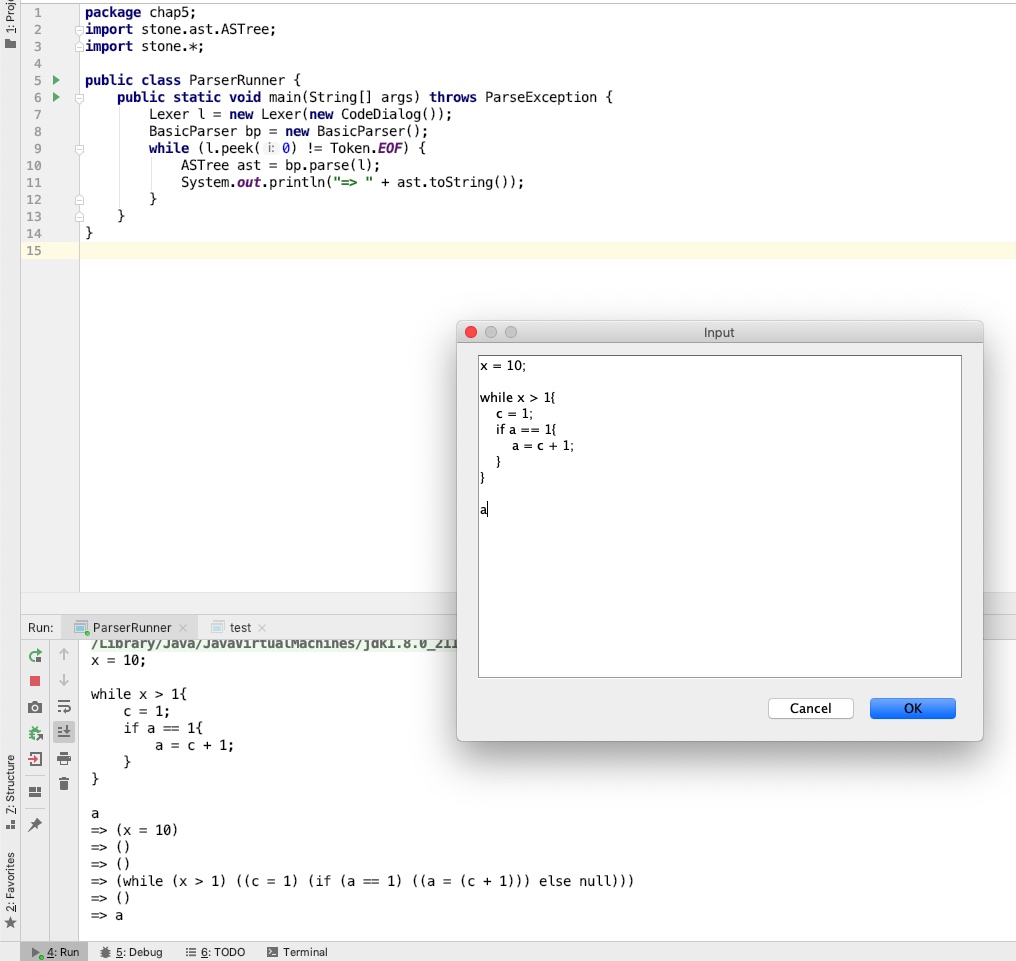
最后匹配的结果
1 | => (x = 10) |
原来折腾了半天,只是为了得到和Lisp原有的语法(S表达式)差不多的结构。