编译原理笔记 - 词法分析
前言
学习的资料是日本人写的那本 《两周自制脚本语言》,两周这个词给人感觉很浮躁,但书的内容还是很适合初学者的,它教你设计一门叫Stone的语言,语法非常简单,尤其是写起Parser来不会感到头疼。全书只有284页,却涉及到了解释器,虚拟机和编译器,算是比较全面,适合入门。
Token
某一段代码:
1 | while i < 10 { |
词法分析会将它们拆分为:
1 | "while" "i" "<" "10" "{" |
词法分析器将源代码视为字符串,将它们分割为若干单词。
被分割后的单词不是简单的字符串,而是Token对象,它除了记录单词对应的字符串,还会保存单词的类型。
单词的类型
标识符(identifier)指的是变量名、函数名或类名等名称。(包括 + -等)
整型字面量(integer literal)指的是 127 或 2014 等字符序列。
字符串字面量(string literal)是一串用于表示字符串的字符序列。被双引号括起来的就是字符串字面量。
双引号之间可以使用 \n 、" 与 \ 这三种类型的转义字符。
正则表达式
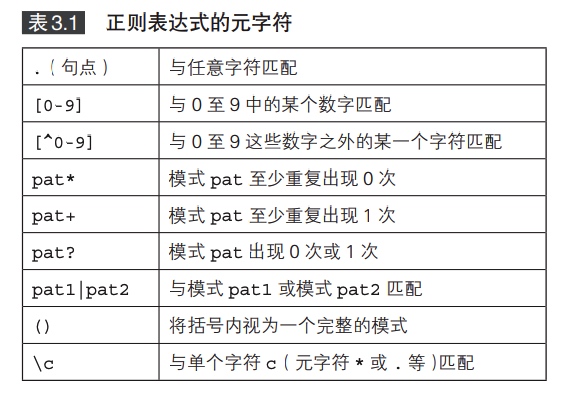
匹配整型字面量:
1 | [0-9]+ |
0 到 9 中取出1个或以上的数字,就能构成一个整型字面量。
匹配标识符:
1
[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||\p{Punct}
这个正则表达式表示至少需要一个字母、数字、下划线或符号,且首字符不能是数字。最后的 \p{Punct} 表示与任意一个符号字符匹配。
匹配字符串:
1
"(\\"|\\\\|\\n|[^"])*"
看上去复杂的一批,不过不必过于深究。
这是一个 “(pat)*” 形式的模式。其中,模式 pat 与 "、\ 、\n 或除 “ 之外任意一个字符匹配。
反斜杠 \ 具有特殊的含义,因此在正则表达式中需要通过 \ 的方式转义,使整个模式变得复杂。
词法分析程序
笔记只记录重要的代码,完整代码请看书。
regexPat 就是最终实现好的正则表达式。
queue是用于保存Token的数组。
LineNumberReader reader 用于逐行读取代码。
1 | public class Lexer { |
read 方法可以从源代码头部开始逐一获取单词。调用 read 时将返回一个新的单词。
调用fillQueue这种操作简单说就是:判断Queue里还有没有Token,有的话依次打印并删除,没有的话就调用readline读下一行。
1 | public Token read() throws ParseException { |
readline 用来读取一行,然后通过正则表达式循环匹配,如果匹配到了就调用addToken。
1 | private void readline() throws ParseException { |
addToken负责判断匹配到的字面类型是什么,是数字,字符串,还是标识符?并选择相应的函数生成token,并将token加入到queue中。
1 | private void addToken(int lineNo, Matcher matcher) { |
更多的函数我就不贴了,因为理解起来非常容易。
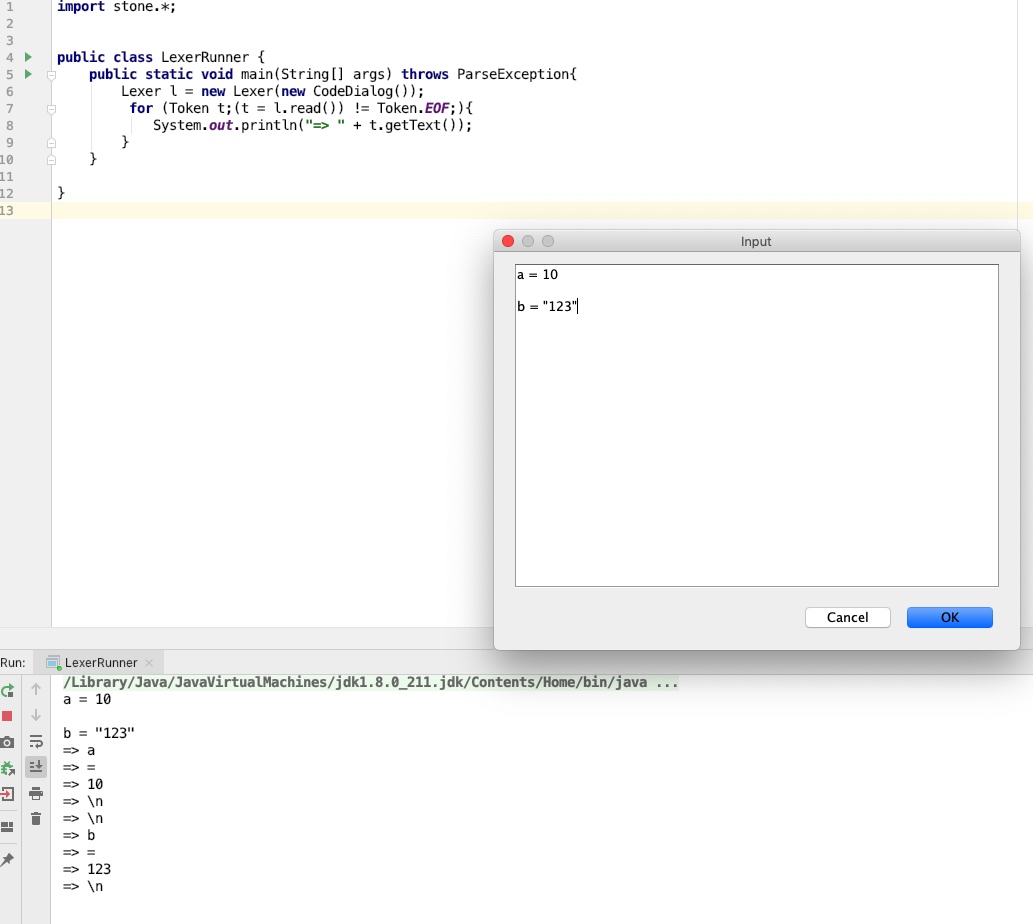
测试效果
学习资料:
两周自制脚本语言